


Introduction
In the realm of data-driven decision-making, managing data effectively is paramount. As organizations gather and analyze vast amounts of data to extract meaningful insights, maintaining control over data versions becomes essential. This is where the concept of data version control steps in, offering a streamlined approach to data management that ensures accuracy, reproducibility, and collaboration. In this article, we delve into the significance of effective data version control and how it can revolutionize the way businesses handle their data assets.
Understanding Data Version Control
Version control systems have long been a staple in software development, enabling teams to collaborate, track changes, and revert to previous states of code effortlessly. Data version control extends this concept to the realm of data science and analytics. It allows teams to keep track of various versions of datasets, models, and associated code, fostering better collaboration, reproducibility, and decision-making.
In traditional data management approaches, changes to datasets and models can quickly lead to confusion and errors. Without proper version control, it becomes challenging to understand who made what changes, when those changes were made, and why they were made. This lack of transparency can result in wasted time, duplicated efforts, and compromised data integrity.
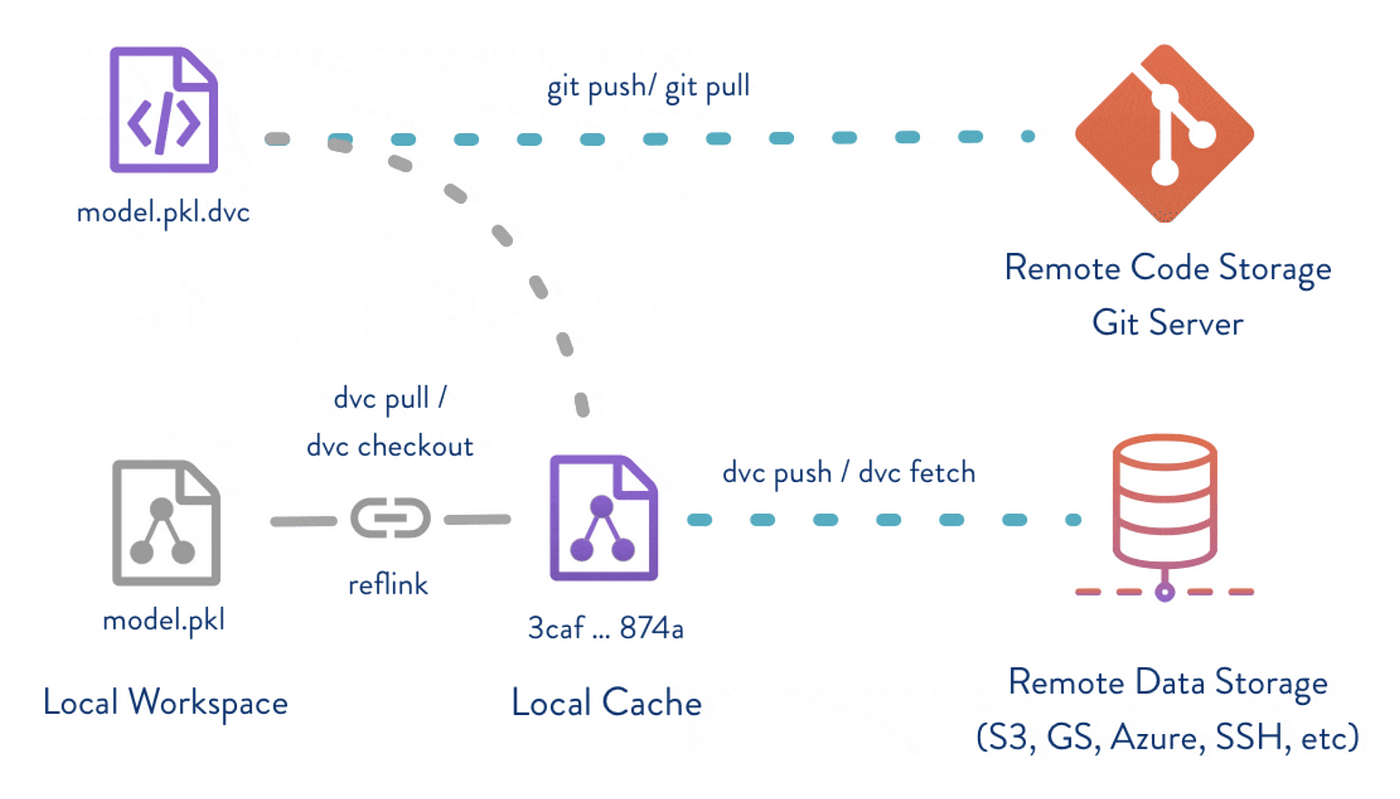
The Benefits of Data Version Control
Implementing data version control offers a range of benefits that significantly enhance data management processes. It largely serves to help improve how teams can work together more effectively and efficiently through the entire SDLC. Here are some of the benefits:
Collaboration: Data version control encourages collaboration by enabling multiple team members to work on the same dataset simultaneously without the fear of conflicting changes. It allows for seamless merging of changes and resolves conflicts efficiently.
Reproducibility: With proper version control, it becomes possible to recreate specific analysis results by referring to the exact version of the dataset, code, and models that were used. This is crucial for validating findings, sharing insights, and ensuring research integrity.
Traceability: Data version control provides a clear history of changes made to datasets and models over time. This traceability is invaluable for auditing purposes, regulatory compliance, and identifying the source of issues that may arise in the data analysis pipeline.
Error Management: When errors or unexpected outcomes occur during data analysis, having access to previous versions allows teams to pinpoint the source of the problem more easily and revert to a known working state.
Experimentation: Data scientists often experiment with different techniques and models. With version control, they can create branches to test new approaches while preserving the original version. This promotes innovation without compromising the existing analysis.
How Data Version Control Works: Streamlining Data Management
At its core, data version control operates on the principles of traditional version control systems while catering to the unique challenges posed by managing data. Understanding how it works is essential for effectively implementing it within your data management processes.
Data Storage and Versioning
Data version control systems store datasets, models, and associated code in a central repository, much like traditional version control systems store code. However, unlike plain text files in code repositories, datasets are often large binary files, which can be challenging to manage efficiently. To address this challenge, data version control integrates with Git Large File Storage (LFS) or similar technologies that are designed to handle large files effectively.
import dvc.api
# Defining the remote data repository
remote_repo = 'https://remote-data-repo-url.com'
# Fetching the data file from a specific version/commit
data_version = 'v1'
data_path = 'data/data.csv'
data_url = dvc.api.get_url(path=data_path, repo=remote_repo, rev=data_version)
# Your data processing and analysis code here...
# For example:
# import pandas as pd
# data = pd.read_csv(data_url)
# ... perform analysis ...
print("Data processing and analysis completed.")
In this example, the dvc.api.get_url() function retrieves a specific version of a data file from a remote repository. You would replace ‘https://remote-data-repo-url.com’ with the actual URL of your remote data repository, ‘v1’ with the desired version or commit ID, and ‘data/data.csv’ with the actual path to your data file within the repository.
This code snippet demonstrates how you can use data version control to fetch a specific version of a data file and then process and analyze the data. The versioned data file ensures that you’re working with a consistent dataset, enhancing reproducibility and data integrity in your analysis.
Commits and Versioning
In data version control, a “commit” is a snapshot of the entire state of the data, code, and models at a specific point in time. Each commit is associated with a unique identifier and metadata, including a commit message that describes the changes made. This system allows users to track the evolution of datasets, code, and models over time.
Branching and Merging
Data version control supports branching and merging, allowing multiple lines of development to coexist. A branch is a separate line of development that can be used to experiment with new ideas or approaches. Once the changes in a branch are tested and validated, they can be merged back into the main branch, ensuring that only well-tested changes become part of the primary analysis.
Tagging and Releases
Tags and releases in data version control serve the same purpose as in traditional version control systems. They allow you to mark specific commits as significant milestones, such as a completed analysis, a version that was shared with stakeholders, or a particular model’s iteration. Tags and releases make it easier to refer back to specific points in the project’s history.
# Suppose you're in the root directory of your DVC project
# Tagging a specific version
dvc tag create my_analysis_v1
# Making a release for a specific version
dvc release create my_analysis_release_v1 my_analysis_v1
# Pushing the tags and releases to a remote repository
dvc push --tags
In this example, we’re using data version control’s command-line interface to create tags and releases. Here’s what’s happening step by step:
dvc tag create my_analysis_v1
This command creates a tag named my_analysis_v1 for the current state of your data version control project. Tags are used to mark significant points in your project’s history, making it easy to refer back to specific versions.
dvc release create my_analysis_release_v1 my_analysis_v1
This command creates a release named my_analysis_release_v1 based on the existing tag my_analysis_v1. Releases are collections of versions that are considered stable and suitable for sharing with others.
dvc push –tags
This command pushes both the tags and releases to a remote repository. By pushing the tags and releases, you ensure that others can access and reference these specific points in your project’s history.
Data Lineage and Dependency Tracking
One of the unique features of data version control is its ability to manage data lineage and track dependencies between various components of a data project. It records which datasets were used as inputs for specific analysis scripts and models, ensuring that the project’s evolution can be easily traced back to its data sources.
Reproducibility and Data Retrieval
With data version control, reproducing previous analyses becomes straightforward. By checking out a specific commit or version, you can recreate the exact state of the data, code, and models that were used at that time. This level of reproducibility is crucial for verifying results, collaborating effectively, and meeting regulatory or compliance requirements.
Collaboration and Remote Repositories
Just like in software development, data version control supports collaboration among team members. Data scientists, analysts, and other stakeholders can work on the same dataset simultaneously, and changes can be merged seamlessly. Remote repositories, similar to GitHub or GitLab repositories, allow team members to access and contribute to the project from different locations.
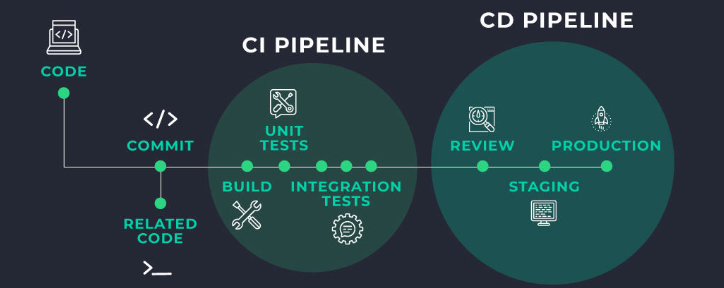
Continuous Integration and Automation
Integrating data version control with continuous integration (CI) and continuous delivery (CD) pipelines further streamlines data management. CI/CD ensures that changes to data, code, or models are automatically tested and validated, reducing the likelihood of errors and inconsistencies.
Conclusion
In the era of big data and advanced analytics, efficient data management is a cornerstone of success. Data version control offers a structured and organized approach to managing data throughout its lifecycle, enhancing collaboration, reproducibility, and error management. By embracing data version control tools and practices, organizations can streamline their data management processes, improve decision-making, and maintain a clear and accurate record of their data-related activities. As data continues to grow in complexity and importance, implementing effective data version control will become an increasingly valuable asset for organizations seeking to harness the power of their data.